Index Once, Search Many
I’ve got documents that go back 20 years or more. Thousands of them. Work and fun ones. Of all file types (.doc, .docx, .pdf, .xls, .xlsx, .ppt, .txt etc etc). I knew that somewhere in that large collection was a piece about a mystery near Hanging Rock; not at hanging rock, near it. It was about the road that appears to allow things to roll up-hill, including cars.
But where to begin? I didn’t know the name of the document (file) nor where in my system it could possibly be. And when I say the system, I’ve got documents/files scattered over four or five main places, including – unfortunately – inside zip files.
What I’d ideally like is a program to read every document and index all the words. Do that once – for my huge archives. Take your time to do that one-off task, but then I can quickly search the contents.
First Attempts
Some years ago at a workplace, I tried a free program called Docfetcher. For some reason, it didn’t work. Possibly to do with the security of their Windows setup . But it looked promising as it’s indexed inside the document including PDF and Word files etc. So I could then say ‘find all my documents that have the words hanging, rock and uphill.’
Just yesterday I had to find a document to do with my car loan. Again it was sort of not that obvious but I found it eventually. By doing a file-name search (not the content inside the file)
So today I thought: I’m going to try and find a program that will index the contents of my thousands of documents, then let me search them…so I don’t have to go through this again.
Because I’m me I dived into a free, enterprise-level indexing engine called Solr. Here is a sample command to get it to work.
java -jar -Dc=sample-items -Dauto example\exampledocs\post.jar example\exampledocs*
Suffice to say I couldn’t even get it to index a small folder of Word and Excel documents.
Docfetcher – Take 2
So I went back to Docfetcher and it is fantastic.
It is really easy to use. You just point it at a folder and say ‘index everything except these file types that I’m not interested in.’ You index once (which is very quick, but obviously grows with the number of files).
So I indexed everything of interest – in a few archive locations – and then searched for hanging rock uphill and it came back with this:
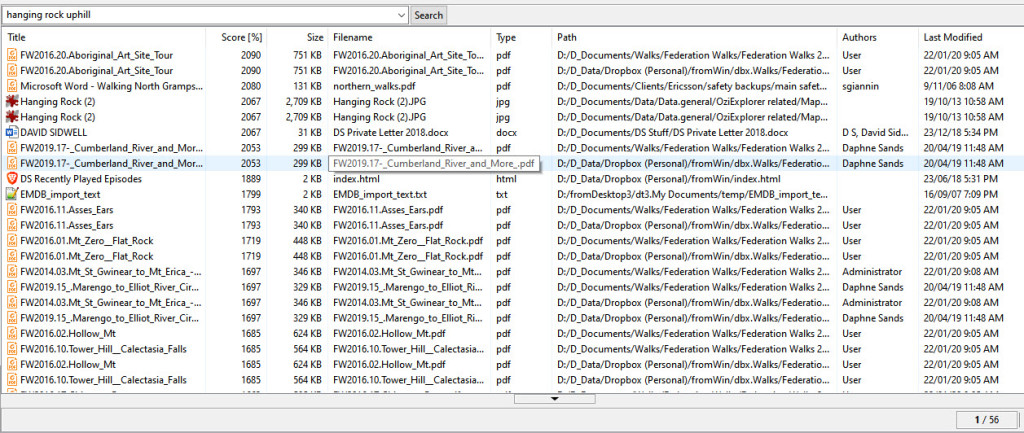
OK, it’s a fair few documents but it’s getting there. So I did a bit of reading and it was easy to fine-tune the search with the big capital AND. It defaults to OR, meaning ‘documents with contents including hanging OR rock OR uphill‘. So, a document about Ned Kelly would have the word hanging in it (not not rock nor uphill)…and be returned.
With that quick change, it amazingly found the old document:

If you look carefully at the details (path), Docfetcher has actually indexed an old Word document that is stored inside a zip file. That is quite amazing. And the whole thing is very quick to do the indexing which you only do the once (these are archives, so don’t change.)
I also indexed my current folder of work, which does change. But it’s very quick to re-index this small folder.
This gave me the confidence to index my main archive, while I walked up to Nelson Place – in the rain – to get a coffee. As I said this is a one-off task. Some stats of that archive:
- 30,711 files (!)
- 27 GB
- 56 minutes to index
But searches take a fraction of a second. I can happily say mission accomplished.
Oh yeah, Miranda, it’s an optical illusion.